System Design — ChatGPT
End-to-end architecture for a large-scale, real-time AI chat service.
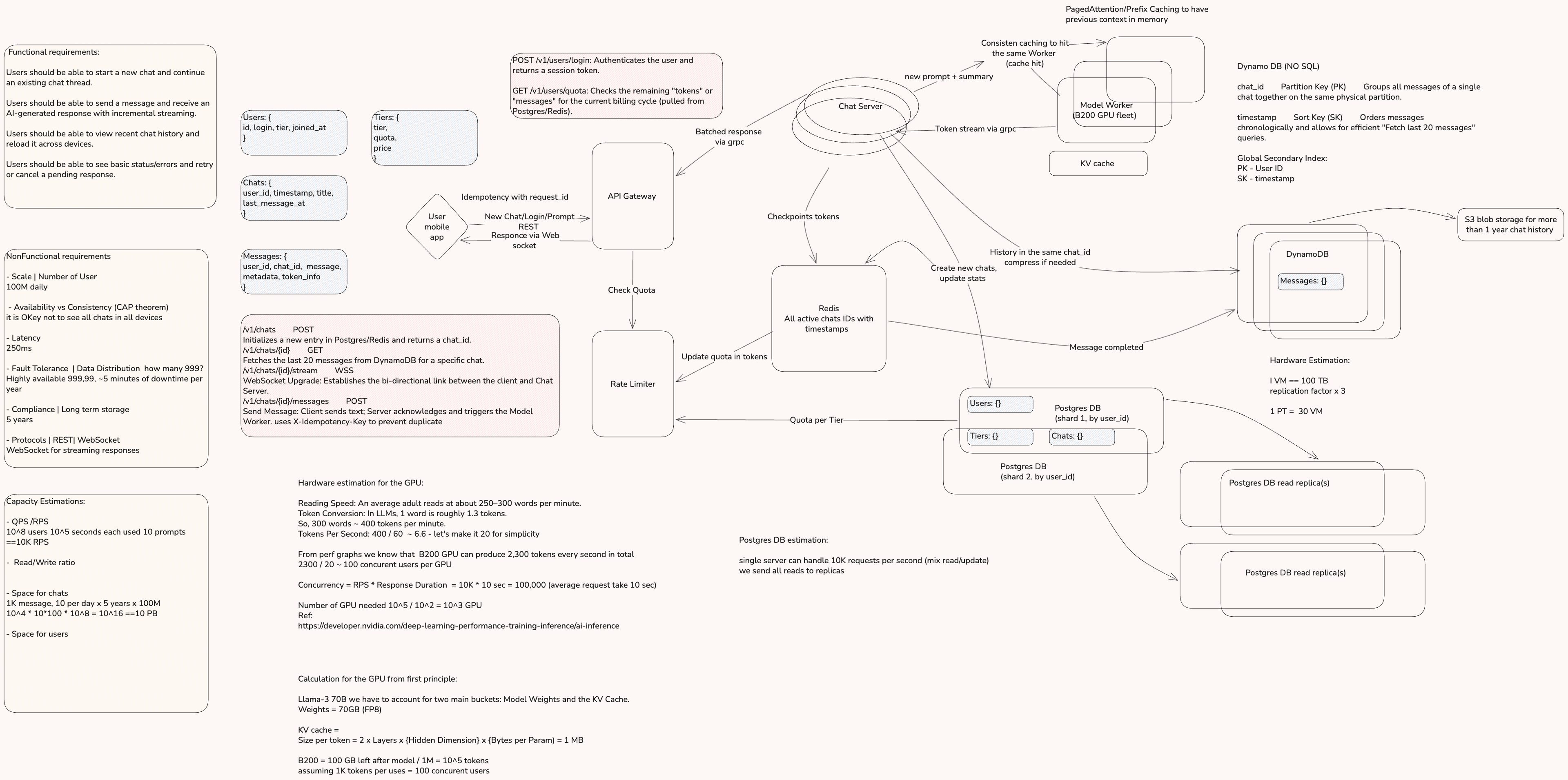
High-Level System Flow
The system follows a hybrid REST and WebSocket architecture to handle the lifecycle of an AI chat session.
Ingress & Control Plane
Requests from the mobile app hit the API Gateway. This layer handles authentication and coordinates with the Rate Limiter, which fetches quota data from Redis (backed by Postgres) to ensure the user hasn't exceeded their tier limits.
Session Management
To prevent duplicate work and double-billing, the system uses Idempotency keys. Before processing a message, the Chat Server checks a unique request_id in Redis.
The Data Plane (Streaming)
For low-latency responses, a persistent WebSocket connection is established. This allows the AI to stream tokens incrementally, significantly improving the user's perceived performance.
Compute: The GPU Fleet
The requirement for 1,000 NVIDIA B200 GPUs is derived from Little's Law ($L = \lambda W$):
Capacity Planning via Little's Law
Hardware Optimizations
First-Principle Memory Scaling
A Llama-3 70B model in FP8 takes 70 GB for weights, leaving ~110 GB for the KV Cache. Using PagedAttention, each token consumes ~1 MB (conservative estimate), allowing for 100 concurrent users per GPU.
Prefix Caching
To minimize redundant math, the Model Workers use Prefix Caching. By using Consistent Hashing (by chat_id) at the Load Balancer, a user's messages always land on the same worker, maximizing KV Cache hits and reducing Time to First Token (TTFT).
Storage Architecture
A multi-tiered storage strategy handles a projected 10 PB of data over 5 years.
Postgres
Stores relational data like user profiles and billing tiers. To handle 100M users, it is sharded by user_id and utilizes Primary-Replica sets for high availability and read scaling.
DynamoDB
Stores the actual message history. Chosen for its horizontal scalability. Estimated 10 PB of total storage, which translates to roughly 300 physical machines (accounting for 3x replication).
S3
To manage costs, history older than 1 year is offloaded from DynamoDB to S3 Blob Storage.
Redis
Tracks active session IDs, idempotency keys, and temporary token quotas.
Reliability and Fault Tolerance
Self-Healing DBs
If a Postgres Primary fails, an automated Failover promotes a replica to primary.
Blast Radius Reduction
Sharding ensures that a failure in one database partition only affects a small subset of users.
Stateless Retries
If a Model Worker node fails, the Consistent Hashing simply remaps the chat_id to a new healthy node. The first request is a "cache miss," but the system remains operational.